Definicje
Niech
 będzie przestrzenią liniową nad ciałem
będzie przestrzenią liniową nad ciałem 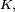 zaś
zaś  oznacza pewien jej endomorfizm, tzn. przekształcenie liniowe tej przestrzeni w siebie. Jeśli dla pewnego niezerowego wektora
oznacza pewien jej endomorfizm, tzn. przekształcenie liniowe tej przestrzeni w siebie. Jeśli dla pewnego niezerowego wektora  przestrzeni spełniony jest warunek
przestrzeni spełniony jest warunek

 jest pewnym skalarem, to nazywa się wektorem własnym, a nazywa się wartością własną przekształcenia
jest pewnym skalarem, to nazywa się wektorem własnym, a nazywa się wartością własną przekształcenia 
Danej wartości własnej
operatora odpowiada zbiór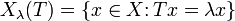
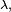 gdyż tworzy on domkniętą podprzestrzenią liniową przestrzeni
gdyż tworzy on domkniętą podprzestrzenią liniową przestrzeni  Jej wymiar nazywa się wielokrotnością wartości własnej
Jej wymiar nazywa się wielokrotnością wartości własnej 
Często zakłada się, że
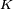 jest ciałem liczb rzeczywistych bądź zespolona, zaś na
określona jest topologia liniowa. W zastosowaniach (np. równania
różniczkowe) bada się często wartości własne operatorów liniowych
określonych na przestrzeniach Banacha, Hilberta itp. W dalszej części
artykułu będziemy zakładać ogólnie, że jest pewną przestrzenią Banacha, a
jest ciałem liczb rzeczywistych bądź zespolona, zaś na
określona jest topologia liniowa. W zastosowaniach (np. równania
różniczkowe) bada się często wartości własne operatorów liniowych
określonych na przestrzeniach Banacha, Hilberta itp. W dalszej części
artykułu będziemy zakładać ogólnie, że jest pewną przestrzenią Banacha, a  jest ustalonym operatorem liniowym i ciągłym.
jest ustalonym operatorem liniowym i ciągłym.Własności
- Jeżeli jest samosprzężonym operatorem liniowym na przestrzeni Hilberta
 to wartości własne tego operatora są rzeczywiste, ponadto wektory
własne, odpowiadające różnym wartościom własnym są ortogonalne.
to wartości własne tego operatora są rzeczywiste, ponadto wektory
własne, odpowiadające różnym wartościom własnym są ortogonalne. - Jeżeli
 jest wartością własną operatora
jest wartością własną operatora  to
to  (założenie zupełności przestrzeni jest tu nieistotne).
(założenie zupełności przestrzeni jest tu nieistotne). - Liczba jest wartością własną operatora wtedy i tylko wtedy, gdy operator
 nie jest różnowartościowy.
nie jest różnowartościowy. - Wektory własne odpowiadające różnym wartościom własnym są liniowo niezależne.
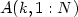
- Jeśli macierz
 potraktować jako macierz przekształcenia liniowego pewnej przestrzeni liniowej
potraktować jako macierz przekształcenia liniowego pewnej przestrzeni liniowej  to wektory własne odpowiadające tej samej wartości własnej tworzą podprzestrzeń.
to wektory własne odpowiadające tej samej wartości własnej tworzą podprzestrzeń. - Jeśli suma wymiarów podprzestrzeni z powyższej własności jest równa wymiarowi to wektory własne odpowiadające różnym wartościom własnym tworzą bazę tej przestrzeni
 . Musimy zatem wyznaczyć t dla ktorego
. Musimy zatem wyznaczyć t dla ktorego 


![P[(Y \ge t) \vee (Y \le -t)] = 0{,}02](http://putwiki.informatyka.org/images/math/d/6/1/d615fe8466003d7e0504faf6069db662.png)




 , w przeciwnym wypadku przy zadanej istotności
, w przeciwnym wypadku przy zadanej istotności 










 i następnie
i następnie 








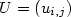
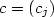





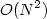









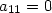
 oraz
oraz  , więc pierwszy wiersz
, więc pierwszy wiersz  , więc pierwsza kolumna
, więc pierwsza kolumna  przez element na diagonali
przez element na diagonali  ,
,
 , a więc znalezienie podmacierzy
, a więc znalezienie podmacierzy  oraz
oraz  sprowadza się do znalezienia rozkładu LU zmodyfikowanego bloku
sprowadza się do znalezienia rozkładu LU zmodyfikowanego bloku 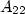 macierzy
macierzy  . Macierz
. Macierz  nazywamy uzupełnieniem Schura.
nazywamy uzupełnieniem Schura.

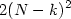

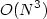 ;
;
 :
:  :
: 
 szukamy elementu o największym module (taki element, na mocy założenia nieosobliwości macierzy, jest niezerowy) --- to jest właśnie element główny
szukamy elementu o największym module (taki element, na mocy założenia nieosobliwości macierzy, jest niezerowy) --- to jest właśnie element główny
 z wierszem, w którym znajduje się element główny
z wierszem, w którym znajduje się element główny

 jest pewną (zerojedynkową) macierzą permutacji (tzn. macierzą
identyczności z przepermutowanymi wierszami).
jest pewną (zerojedynkową) macierzą permutacji (tzn. macierzą
identyczności z przepermutowanymi wierszami).
 równań
liniowych nie może być wyższego rzędu niż minimalny koszt mnożenia dwóch
macierzy
równań
liniowych nie może być wyższego rzędu niż minimalny koszt mnożenia dwóch
macierzy  (algorytm Strassena). Bardziej skomplikowany (i praktycznie
nieimplementowalny) algorytm Coppersmitha i Winograda daje nawet koszt
(algorytm Strassena). Bardziej skomplikowany (i praktycznie
nieimplementowalny) algorytm Coppersmitha i Winograda daje nawet koszt
 . Równania liniowe daje się więc (teoretycznie) rozwiązać
kosztem
. Równania liniowe daje się więc (teoretycznie) rozwiązać
kosztem