Czasem zadania obliczeniowe wymagają wykonania naprawdę wielkiej liczby obliczeń zmiennoprzecinkowych, przy czym wiele znanych, matematycznie równoważnych metod rozwiązywania takich zadań, ma diametralnie różne własności numeryczne. Bardzo ważną klasą takich intensywnych obliczeniowo zadań jest rozwiązywanie układów równań liniowych

 jest nieosobliwą macierzą
jest nieosobliwą macierzą  , a dany wektor prawej strony
, a dany wektor prawej strony  .
.
W praktyce spotyka się zadania z
 . Zdarzają się także czasem szczególne macierze o wymiarach nawet rzędu
. Zdarzają się także czasem szczególne macierze o wymiarach nawet rzędu  !
Rozwiązywanie układów równań liniowych jest sercem wielu innych
algorytmów numerycznych --- podobno szacuje się, że około 75 procent
czasu obliczeniowego superkomputerów jest wykorzystywanych właśnie na
rozwiązywanie takich zadań. O tym, jak skutecznie rozwiązywać takie zadania, jakie mogą czekać nas niespodzianki, traktują: ten i następne trzy wykłady.
!
Rozwiązywanie układów równań liniowych jest sercem wielu innych
algorytmów numerycznych --- podobno szacuje się, że około 75 procent
czasu obliczeniowego superkomputerów jest wykorzystywanych właśnie na
rozwiązywanie takich zadań. O tym, jak skutecznie rozwiązywać takie zadania, jakie mogą czekać nas niespodzianki, traktują: ten i następne trzy wykłady.
Okazuje się, że kilka znanych w matematyce sposobów rozwiązywania układów równań liniowych, takich jak:
- metoda wyznacznikowa (wzory Cramera)
- obliczenie macierzy
 i następnie
i następnie 
Proste układy równań
Niektóre układy równań można bardzo łatwo rozwiązać. Zgodnie z zasadą, żetrudne zadania rozwiązujemy sprowadzając je do sekwencji łatwych zadań,w dalszej kolejności pokażemy, jak dowolny układ równań sprowadzić do sekwencji dwóch (czasem trzech) łatwych do rozwiązania układów równań. Ale... jakie układy równań są "łatwe"?
Układy z macierzą trójkątną
Rozważmy układ z macierzą trójkątną. Będą nas szczególnie interesować macierze
trójkątne górne, dla których  gdy
gdy  , oraz
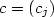
macierze trójkątne dolne z jedynkami na przekątnej, tzn.
,
, oraz
macierze trójkątne dolne z jedynkami na przekątnej, tzn.
,  , oraz
, oraz  . Macierze pierwszego rodzaju
będziemy oznaczać przez
. Macierze pierwszego rodzaju
będziemy oznaczać przez  , a drugiego rodzaju przez
, a drugiego rodzaju przez  .
.


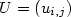 ,
, 
Układy z macierzą ortogonalną
Równie tanio można rozwiązać układ równań
 jest macierzą ortogonalną, to znaczy
jest macierzą ortogonalną, to znaczy  . Rzeczywiście, z
ortogonalności wynika wprost, że
. Rzeczywiście, z
ortogonalności wynika wprost, że

 można wyznaczyć kosztem takim, jak koszt mnożenia macierzy
przez wektor, czyli
można wyznaczyć kosztem takim, jak koszt mnożenia macierzy
przez wektor, czyli 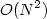 operacji.
operacji.
Podobnie, gdy
 jest unitarna, to znaczy
jest unitarna, to znaczy  (przypomnijmy:
(przypomnijmy:  oznacza macierz sprzężoną do , tzn. taką, że
oznacza macierz sprzężoną do , tzn. taką, że  ),
rozwiązaniem układu równań jest
),
rozwiązaniem układu równań jest

Metoda eliminacji Gaussa
W ogólnym przypadku, bardzo dobrym algorytmem numerycznego rozwiązywania układu równań (z jedynkami na diagonali) oraz trójkątnej górnej takich, że
(z jedynkami na diagonali) oraz trójkątnej górnej takich, że

Przypuśćmy, że taki rozkład
 istnieje (nie musi!). Wówczas, zapisując macierze w postaci blokowej,
eksponując pierwszy wiersz i pierwszą kolumnę zaangażowanych macierzy,
mamy
istnieje (nie musi!). Wówczas, zapisując macierze w postaci blokowej,
eksponując pierwszy wiersz i pierwszą kolumnę zaangażowanych macierzy,
mamy
 przez ) wynika, że
przez ) wynika, że
-
 oraz
oraz  , więc pierwszy wiersz jest kopią pierwszego wiersza ,
, więc pierwszy wiersz jest kopią pierwszego wiersza ,
-
 , więc pierwsza kolumna powstaje przez podzielenie wszystkich elementów wektora
, więc pierwsza kolumna powstaje przez podzielenie wszystkich elementów wektora  przez element na diagonali
przez element na diagonali  ,
,
-
 , a więc znalezienie podmacierzy
, a więc znalezienie podmacierzy  oraz
oraz  sprowadza się do znalezienia rozkładu LU zmodyfikowanego bloku
sprowadza się do znalezienia rozkładu LU zmodyfikowanego bloku 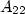 macierzy , wymiaru
macierzy , wymiaru  . Macierz
. Macierz  nazywamy uzupełnieniem Schura.
nazywamy uzupełnieniem Schura.
Ponadto zauważmy, że opisany algorytm możemy wykonać in situ (w miejscu), nadpisując elementy
elementami macierzy i (jedynek z diagonali nie musimy pamiętać, bo wiemy a priori, że tam są). Dzięki temu dodatkowo zaoszczędzimy pamięć.
Łatwo przekonać się, że
 -ty obrót zewnętrznej pętli (tzn. -ty krok
algorytmu rozkładu LU) kosztuje rzędu
-ty obrót zewnętrznej pętli (tzn. -ty krok
algorytmu rozkładu LU) kosztuje rzędu 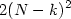 operacji arytmetycznych, skąd łączny koszt tego algorytmu rozkładu LU wynosi około
operacji arytmetycznych, skąd łączny koszt tego algorytmu rozkładu LU wynosi około  .
.
Jeśli więc do rozwiązywania układu równań
wykorzystamy rozkład LU, to mamy następujące zestawienie kosztów:
- Koszt znalezienia rozkładu :
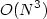 ;
;
- Koszt rozwiązania układu
 : ;
: ;
- Koszt rozwiązania układu
 : .
: .
.
Wybór elementu głównego
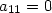
Opisany powyżej algorytm rozkładu LU czasem może się niestety załamać: mianowicie wtedy, gdy napotka w czasie działania zerowy element w lewym górnym rogu zmodyfikowanej podmacierzy. Na przykład, macierz
 ... Ale wystarczy zamienić ze sobą
wiersze macierzy
(to znaczy, w układzie równań, zamienić kolejność równań), a dostaniemy
macierz, z którą nasz algorytm poradzi sobie bez problemu! Musimy więc
--- aby stosować eliminację Gaussa do dowolnych macierzy
nieosobliwych --- dokonywać takich permutacji równań, by elementem,
przez który dzielimy, była zawsze liczba niezerowa (jest to możliwe, na
mocy założenia nieosobliwości macierzy).
... Ale wystarczy zamienić ze sobą
wiersze macierzy
(to znaczy, w układzie równań, zamienić kolejność równań), a dostaniemy
macierz, z którą nasz algorytm poradzi sobie bez problemu! Musimy więc
--- aby stosować eliminację Gaussa do dowolnych macierzy
nieosobliwych --- dokonywać takich permutacji równań, by elementem,
przez który dzielimy, była zawsze liczba niezerowa (jest to możliwe, na
mocy założenia nieosobliwości macierzy).
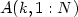
W praktyce obliczeniowej, aby uzyskać algorytm o możliwie dobrych własnościach numerycznych, wykorzystujemy tzw. strategię wyboru elementu głównego w kolumnie. Polega to na tym, że zanim wykonamy
-ty krok algorytmu rozkładu LU,
- w pierwszej kolumnie podmacierzy
 szukamy elementu o największym module (taki element, na mocy założenia nieosobliwości macierzy, jest niezerowy) --- to jest właśnie element główny
szukamy elementu o największym module (taki element, na mocy założenia nieosobliwości macierzy, jest niezerowy) --- to jest właśnie element główny
- zamieniamy ze sobą wiersz
 z wierszem, w którym znajduje się element główny
z wierszem, w którym znajduje się element główny
- zapamiętujemy dokonaną permutację, bo potem --- gdy już przyjdzie do rozwiązywania układu równań --- będziemy musieli dokonać analogicznej permutacji wektora prawej strony

gdzie  jest pewną (zerojedynkową) macierzą permutacji (tzn. macierzą
identyczności z przepermutowanymi wierszami).
jest pewną (zerojedynkową) macierzą permutacji (tzn. macierzą
identyczności z przepermutowanymi wierszami).
Oprócz wyboru elementu głównego w kolumnie, stosuje się czasem inne strategie, m.in. wybór w wierszu (analogicznie) oraz tzw. wybór pełny, gdy elementu głównego szukamy w całej podmacierzy,
co znacznie zwiększa liczbę porównań niezbędnych do wskazania elementu
głównego, ale też trochę poprawia własności numeryczne takiego
algorytmu.
W praktyce, do przechowywania całej informacji o wykonanych permutacjach wystarcza pojedynczy wektor.
jest pewną (zerojedynkową) macierzą permutacji (tzn. macierzą
identyczności z przepermutowanymi wierszami).
Oprócz wyboru elementu głównego w kolumnie, stosuje się czasem inne strategie, m.in. wybór w wierszu (analogicznie) oraz tzw. wybór pełny, gdy elementu głównego szukamy w całej podmacierzy
,
co znacznie zwiększa liczbę porównań niezbędnych do wskazania elementu
głównego, ale też trochę poprawia własności numeryczne takiego
algorytmu.
W praktyce, do przechowywania całej informacji o wykonanych permutacjach wystarcza pojedynczy wektor.
Złożoność obliczeniowa zadania rozwiązania układu równań liniowych
Z powyższego wynika, że łączny koszt rozwiązania równania liniowego poprzez rozkład LU wynosi . Można zastanawiać się, jaka jest najmniejsza możliwa liczba operacji zmiennoprzecinkowych potrzebnych do rozwiązania układu równań liniowych.
. Można zastanawiać się, jaka jest najmniejsza możliwa liczba operacji zmiennoprzecinkowych potrzebnych do rozwiązania układu równań liniowych.
Można pokazać, że minimalny koszt rozwiązania układu  równań
liniowych nie może być wyższego rzędu niż minimalny koszt mnożenia dwóch
macierzy . Tymczasem znany jest całkiem prosty algorytm rekurencyjny,
wyznaczający iloczyn dwóch macierzy kosztem
równań
liniowych nie może być wyższego rzędu niż minimalny koszt mnożenia dwóch
macierzy . Tymczasem znany jest całkiem prosty algorytm rekurencyjny,
wyznaczający iloczyn dwóch macierzy kosztem  (algorytm Strassena). Bardziej skomplikowany (i praktycznie
nieimplementowalny) algorytm Coppersmitha i Winograda daje nawet koszt
(algorytm Strassena). Bardziej skomplikowany (i praktycznie
nieimplementowalny) algorytm Coppersmitha i Winograda daje nawet koszt
 . Równania liniowe daje się więc (teoretycznie) rozwiązać
kosztem .
. Równania liniowe daje się więc (teoretycznie) rozwiązać
kosztem .
równań
liniowych nie może być wyższego rzędu niż minimalny koszt mnożenia dwóch
macierzy . Tymczasem znany jest całkiem prosty algorytm rekurencyjny,
wyznaczający iloczyn dwóch macierzy kosztem (algorytm Strassena). Bardziej skomplikowany (i praktycznie
nieimplementowalny) algorytm Coppersmitha i Winograda daje nawet koszt
. Równania liniowe daje się więc (teoretycznie) rozwiązać
kosztem .
Jednak w praktyce nawet prosty algorytm Strassena zazwyczaj nie
jest stosowany.
Wynika to stąd, że ma trochę gorsze własności numeryczne oraz, co
istotniejsze, wymaga dużo dodatkowej pamięci na przechowywanie
pośrednich wyników. Są jednak podejmowane wysiłki, by zmniejszyć te
ograniczenia algorytmu Strassena.
Brak komentarzy:
Prześlij komentarz